This post first appeared on AppNexus’s tech blog.
The impetus for this post was a max heap routine I had to write because libc, unlike the STL, does not support incremental or even partial sorting. After staring at the standard implicit binary heap for a while, I realised how to generalise it to arbitrary arity. The routine will be used for medium size elements (a couple dozen bytes) and with a trivial comparison function; in that situation, it makes sense to implement a high arity heap and perform fewer swaps in return for additional comparisons. In fact, the trade-off is interesting enough that a heapsort based on this routine is competitive with BSD and glibc sorts. This post will present the k-ary heap code and explore the impact of memory traffic on the performance of a few classical sort routines. The worst performing sorts in BSD’s and GNU’s libc overlook swaps and focus on minimising comparisons. I argue this is rarely the correct choice, although our hands are partly tied by POSIX.
A k-ary max heap
The heart of a heap – and of heapsort – is the sift-down function.
I explored the indexing scheme below in details
somewhere else, but the gist of it is
that we work with regular 0-indexed arrays and the children of
heap[i] lie at indices heap[way * i + 1] to heap[way * i + way],
inclusively. Like sifting for regular binary heaps, the routine
restores the max-heap property under the assumption that only the root
(head) may be smaller than any of its children.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
The expected use case for this routine is that compar is a trivial
function (e.g., comparing two longs) and size relatively large, up
to fifty or even a few hundred bytes. That’s why we do some more
work to not only minimise the number of swaps, but also to accelerate
each swap.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
When the data will always be aligned to 16-byte boundaries, we swap
vector registers. Otherwise, we resort to register-size calls to
memcpy(3) – decent compilers will turn them into unaligned accesses
– and handle any slop with byte-by-byte swaps.
It’s a quick coding job to wrap the above in a linear-time heapify
and a heapsort.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 | |
This heap implementation proved more than good enough for our
production use. In fact, it is so efficient that nheapsort is
competitive with battle-tested sort implementations, particularly when
sorting medium or large structs. However, these classical
implementations were primarily tuned with comparison counts in mind…
which I argue is now inappropriate. In the remainder of this post,
I’ll explore the impact of swaps on the performance of sort routines.
Meet the competition
I will compare with the sort routines in two libc: GNU’s glibc and BSD’s (FreeBSD and OS X, at least, and other *BSD I expect) libc. All are more than 20 years old.
The qsort(3) routine in glibc is usually a mergesort that allocates
scratch space. It includes some tests to try and detect out of memory
conditions, but I doubt the logic is very effective on contemporary
hardware and with Linux’s overcommit by default. BSD manpages specify
that qsort(3) is in-place. GNU’s don’t… because glibc’s qsort is not
a quicksort.
I can see many arguments for glibc’s design choice. For one, a nicely tuned mergesort may be quicker than a safe (guaranteed \(\mathcal{O}(n \log n)\) time) quicksort. It also enables msort’s indirect sorting strategy for large elements: when elements span more than 32 chars, the sort phase only manipulates pointers and a final linear-time pass shuffles the actual data in place.
On the other hand, I would be annoyed if qsort triggered the OOM killer.
For this reason, I’ll explicitly consider the real in-place quicksort that gets called when it’s clear that allocating more memory is infeasible. Sadly, I doubt that quicksort received much attention since it was tuned for a Sun 4/260. It’s clearly a product of the 80’s. It has an explicit stack, the recursion order guarantees logarithmic stack depth, the pivot is always chosen with a median of three, and the base case (a partition of 4 or fewer elements) switches to insertion sort.
The code and the very design of the routine seem to completely disregard memory traffic. The swap loop is always char-by-char, and the base case (insertion sort) isn’t actually called when recursion stops at a leaf. Instead, small unsorted partitions are left as is. Insertion sort is only executed at the end, over the whole array: unsorted partitions contain at most 4 elements and are otherwise ordered correctly, so each insertion sort inner loop iterates at most 4 times. This strategy wastes the locality advantage of divide-and-conquer sorts: the insertion sort pass is almost streaming, but it would likely operate on warm data if leaf partitions were sorted on the fly.
It also includes unsafe code like
char *const end_ptr = &base_ptr[size * (total_elems - 1)];
char *tmp_ptr = base_ptr;
char *thresh = min(end_ptr, base_ptr + max_thresh);
I can only pray that compilers never becomes smart enough to exploit
base_ptr + max_thresh to determine that this routine will never sort
arrays of fewer than 4 elements.
glibc’s implementation of inserts only aggravates the problem. After finding a sorted position for the new element, insertion sort must insert it there. Usually one would implement that by copying the new element (one past the end of the sorted section) to a temporary buffer, sliding the tail of the sorted array one slot toward the end, and writing the new element in its expected position. Unfortunately, we can’t allocate an arbitrary-size temporary buffer if our quicksort is to be in-place. The insertion loop in glibc circumvents the problem by doing the copy/slide/write dance… one char at a time. That’s the worst implementation I can think of with respect to memory access patterns. It operates on a set of contiguous addresses (the tail of the sorted array and the new element at its end) with a double loop of strided accesses that still end up touching each of these addresses. When the element size is a power of two, it might even hit aliasing issues and exhaust the associativity of data caches.
The quicksort in *BSD is saner, perhaps because it is still called by
qsort(3). While glibc pays lip service to Bentley and McIlroy’s “Engineering a Sort Function”, BSD actually uses their implementation.
The swap macro works one long at a time if possible, and the
recursive (with tail recursion replaced by a goto) function switches
to insertion sort as soon as the input comprises fewwer than 7
elements. Finally, unlike GNU’s insertion sort, BSD’s rotates in
place with a series of swaps. This approach executes more writes than
glibc’s strided rotations, but only accesses pairs of contiguous addresses.
There’s one tweak that I find worrying: whenever a pivoting step
leaves everything in place, quicksort directly switches to insertion
sort, regardless of the partition size. This is an attempt to detect
pre-sorted subsequences, but malicious or unlucky input can easily
turn BSD’s quicksort into a quadratic-time insertion sort.
GNU’s quicksort finishes with insertion sort because the latter copes well with almost sorted data, including the result of its partial quicksort. BSD’s qsort is a straight, cache-friendly, divide-and-conquer implementation. It looks like it’d make sense to replace its base case with a selection sort: selection sort will perform more comparisons than insertion sort (the latter could even use binary search), but, with a single swap per iteration, will move much less data around. I tried it out and the change had little to no impact, even for large elements.
For completeness’s sake, I’ll also include results with BSD libc’s heapsort and mergesort. The heapsort doesn’t look like it’s been touched in a long while; it too gives compilers licence to kill code, via
/*
* Items are numbered from 1 to nmemb, so offset from size bytes
* below the starting address.
*/
base = (char *)vbase - size;
Even libcs can’t get undefined behaviour straight.
And the test range
Ideally, we could expose the effect of both element size and element count on the performance of these sort routines. However, even if I were to measure runtimes on the cross product of a range of element size, range of element count, and a set of sort routine, I don’t know how I would make sense of the results. Instead, I’ll let element sizes vary from one word to a few hundred bytes, and bin element counts in a few representative ranges:
- Tiny arrays: 4-7 elements.
- X-Small arrays: 8-15 elements;
- Small arrays: 16-31 elements
- Medium arrays: 32-64 elements.
The test program times each sort routine on the same randomly
generated input (sampling with replacement from random(3)), for each
element size. I try and smooth out outliers by repeating this process
(including regenerating a fresh input) 20 times for each element size and
count.
Regardless of the element size, the comparison function is the same:
it compares a single unsigned field at the head of the member. I
chose this comparator to reflect real world workloads in which
comparisons are trivial. When comparisons are slow, element size
becomes irrelevant and classical performance analyses apply.
The idea is to track, within each count bin, relative speedup/slowdown compared to BSD’s quicksort: any difference in multiplicative factors, as a function of element size, should show itself. The element count bins can instead highlight differences in additive factors.
Pretty pictures
A test program logged runtimes for this cross product of all element
sizes from 8 to 512 bytes (inclusively), all element counts (4 to 64,
inclusively), and various sort routines. For each size/count pair,
the program regenerated a number of random(3) input; each sort
routine received a copy of the same input. Given such random input,
we can expect all runtimes to scale with \(\Theta(n\log n)\), and it
makes sense to report cycle counts scaled by a baseline (BSD’s
quicksort).
I compiled each sort routine (with gcc 4.8.2 at -O2) separately from
the benchmark driver. This prevented fancy interprocedural
optimisation or specialisation from taking place, exactly like we
would expect from calling to libc. Everything below reports (scaled)
cycle counts on my machine, an E5-4617. I executed the benchmark with
four processes pinned to different sockets, so the results should
reflect a regular single-threaded setting. I definitely could have
run the benchmark on more machines, but I doubt that the relative
computational overhead of copying structs versus comparing two machine
words have varied much in the past couple years.
Finding the perfect k
I first tested our k-ary heapsort with many values for k: 2-9, 12,
15-17.
When sorting 8-byte values, k doesn’t have too much of an impact.
Nevertheless, it’s clear that large k (12 and over) are slower than even
binary heapsort. The sweetspot seems to be around 4 to 7.
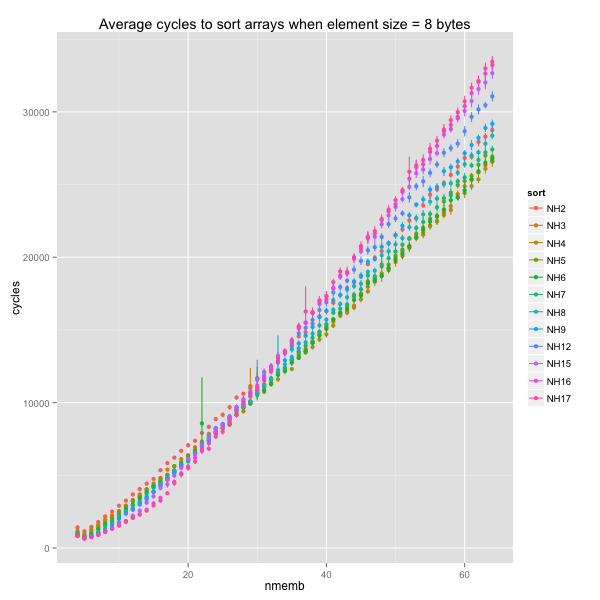
Larger elements (32 and 64 bytes) show that the usual choice of
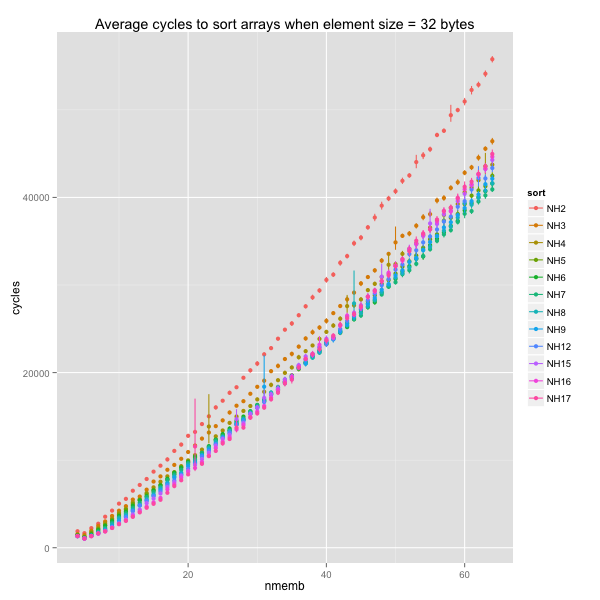
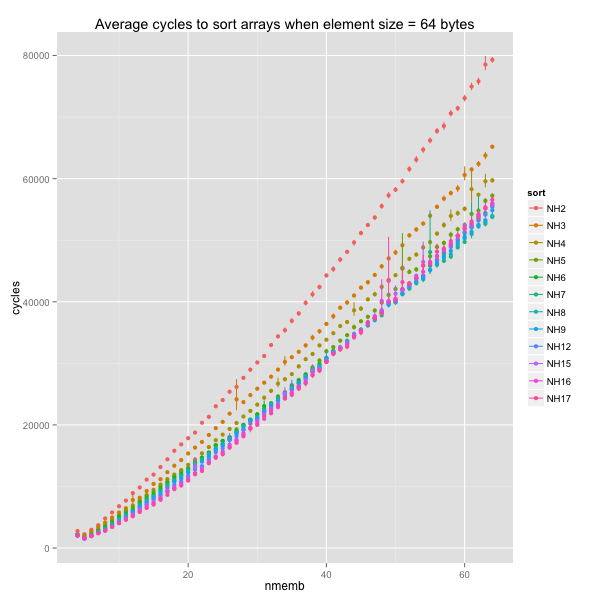
k = 2 causes more than a 30% slowdown when swaps are slow. The
ideal k falls somewhere between 5 and 9 and between 6 and 17.
Finally, at the extreme, with 512 byte elements, binary heapsort is almost twice as slow as 7-ary to 17-ary heapsorts.
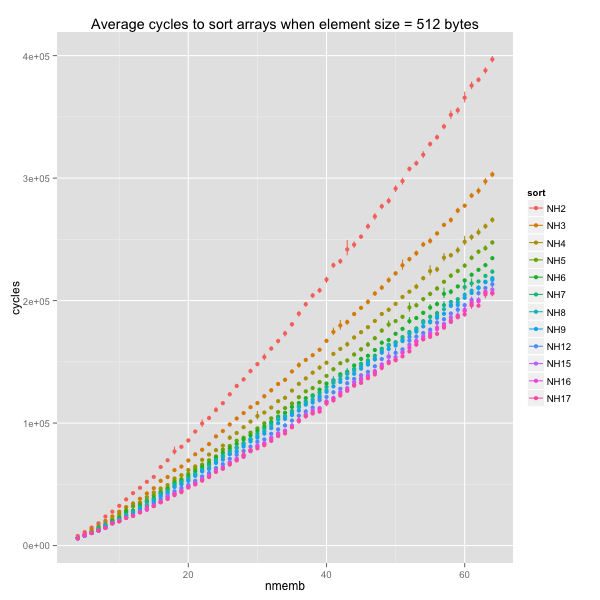
The best choice of k will vary depending on how much slower it is to
swap two elements than to compare them. A fixed value between 5 and 7
should be close to optimal for elements of 8 to 512 bytes.
Tweaks to GNU quicksort
I already mentioned that GNU’s quicksort has a slow swap macro, and that it ends with an insertion sort pass rather than completely sorting recursion leaves. I tested versions of that quicksort with a different swap function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
I also tested versions that only stops recursing on inputs of size 1
(with #define MAX_THRESH 1). This is a simple-minded way to
implement quicksort, but avoids the final insertion sort pass (which
proved too hairy to convert to the new swap function).
When elements are small (8 bytes), the trivial recursion base case (GQL) is a bad idea; it’s slower than the original GNU quicksort (GQ). The new swap function (GQS), however, is always useful. In fact, the combination of trivial base cases and improved swap (GQLS) is pretty much identical to the original GNU quicksort.
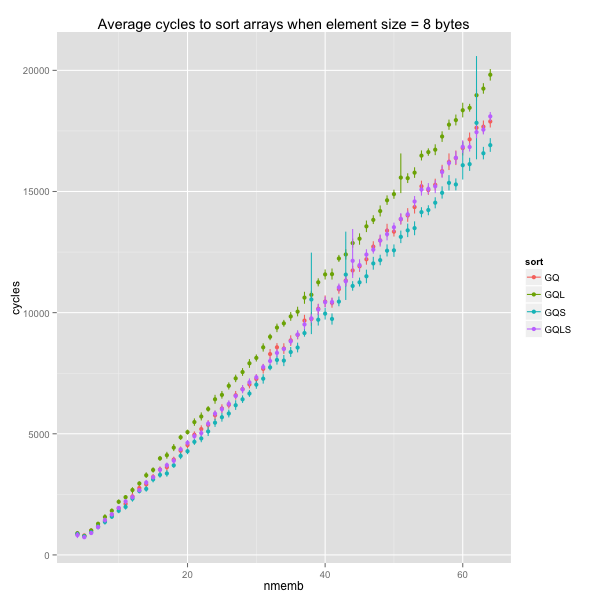
Switching to larger elements (16, 32, 64 or 512 bytes) shakes things up a bit. The impact of faster swaps increases, and GQLS – the version with faster swap and trivial base case – is markedly quicker than the other variants.
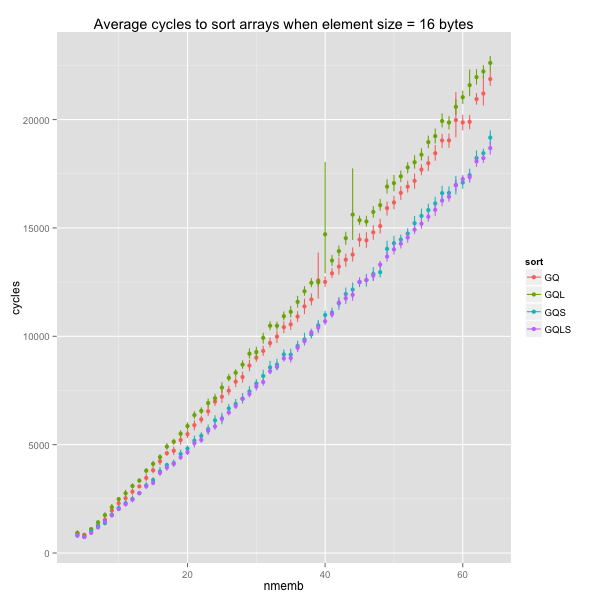
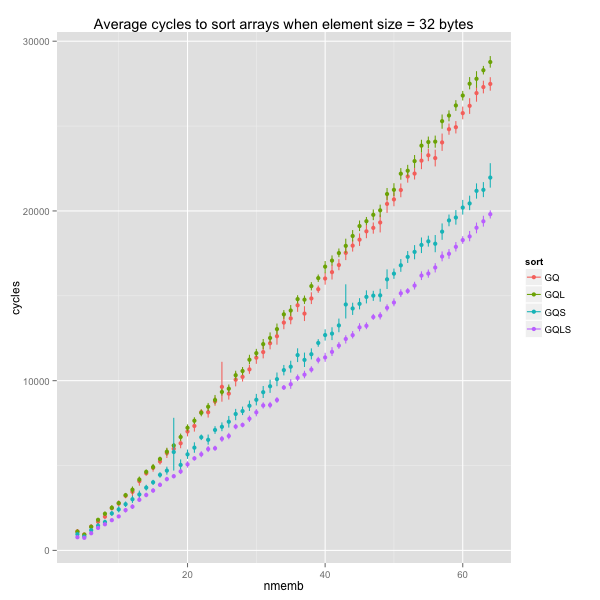
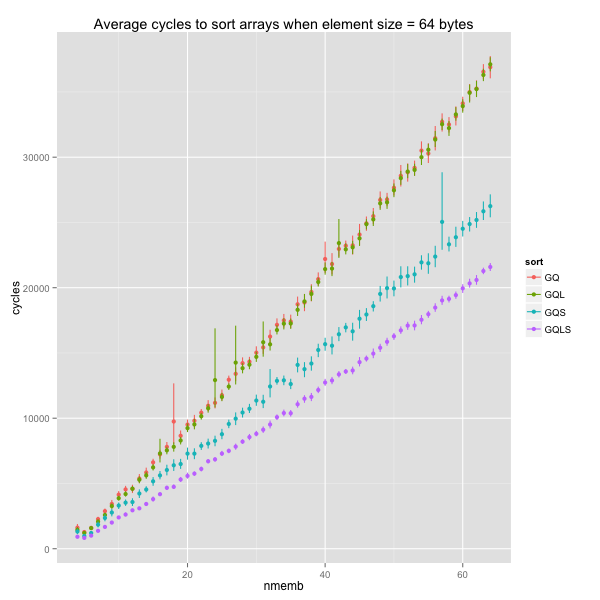
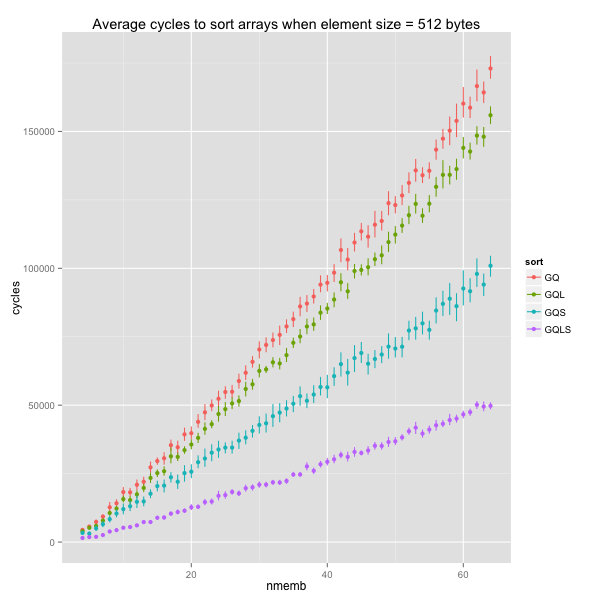
In the sequel, I will only consider the original GNU quicksort (GQ) and the variant with trivial base case and faster swaps. From now on, I’ll refer to that variant as GQ’.
Sanity checking the size bins
I proposed to partition array lengths in 4 bins. For that to work, the behaviour of the sort routines must be fairly homogeneous within each bin.
The graph below fixes the element size at 8 bytes and presents normalised times for a few sort routines and a range of array sizes. We report the (geometric) average of 20 runtimes, scaled by the runtime for BSD quicksort on the same input, on a logarithmic scale. The logarithmic scale preserves the symmetry between a routine that is twice as slow as BSD quicksort (log ratio = 1) and one that is twice as fast (log ratio = -1). The sort routines are:
- GM: GNU mergesort;
- GQ: GNU quicksort;
- GQ’: tweaked GNU quicksort;
- BM: BSD mergesort;
- BH: BSD heapsort;
- NH5: 5-ary heapsort;
- NH7: 7-ary heapsort.
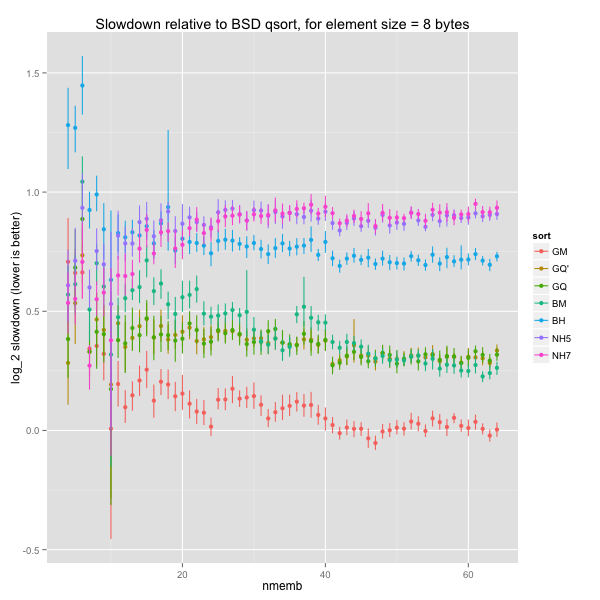
The graph is pretty noisy for smaller arrays, but there’s no obvious discrepancy within size bins. The same holds for larger element sizes (16, 64 and 512 bytes).
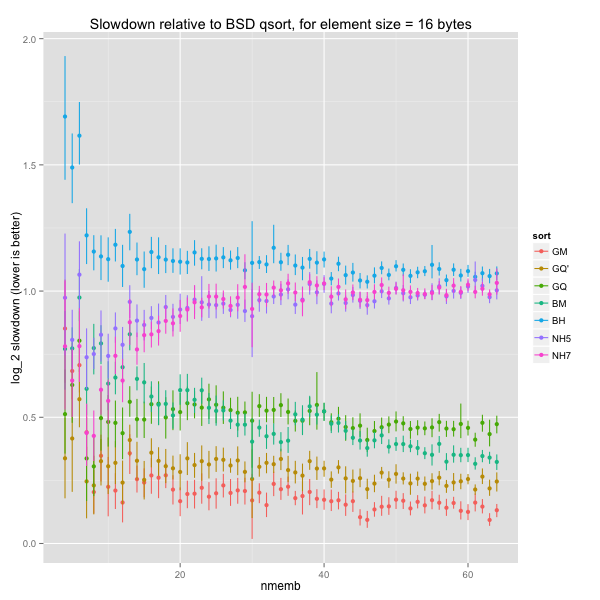
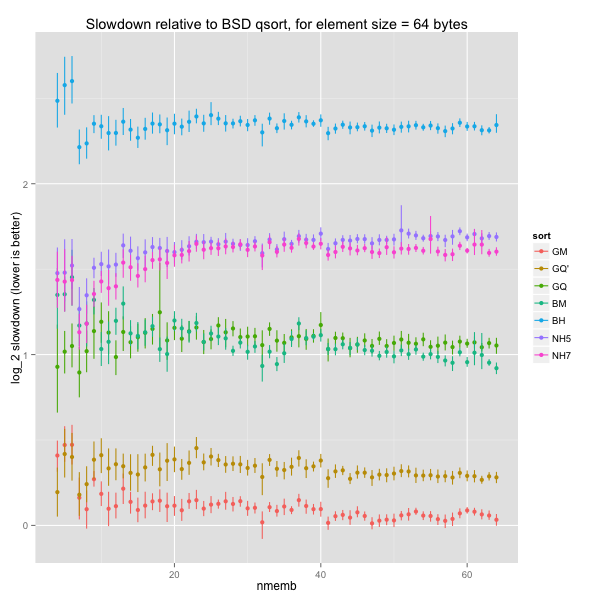
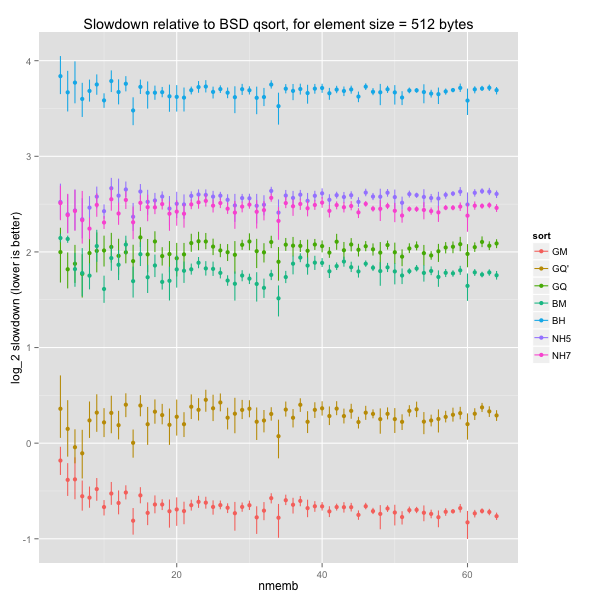
We can already see that BSD’s quicksort is hard to beat on the element sizes considered above.
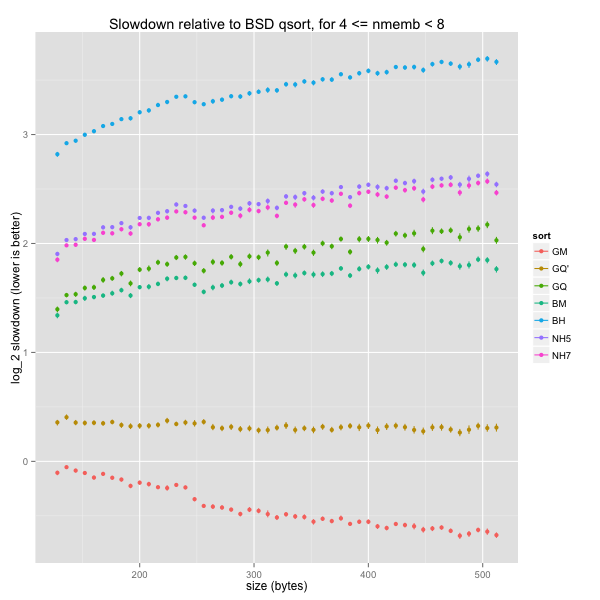
Impact of element size on tiny arrays
The next graph shows the evolution of average (log) normalised sort times for tiny arrays (4-7 elements), as the size of each element grows from 8 to 512 bytes.
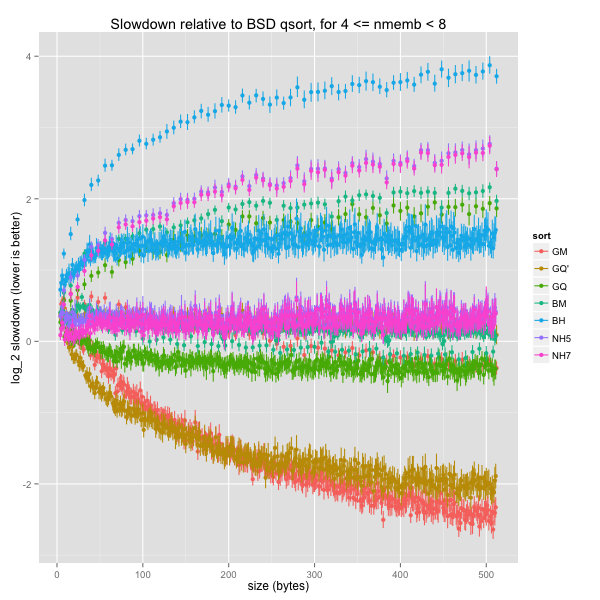
There’s some overplotting, but it’s clear that there are actually two sets of curves: the main one, and another that only comprises sizes that are multiples of 8 (word-aligned). I believe this is caused by special optimisations for nice element sizes in some (but not all) sort routines, including our baseline, BSD’s quicksort.
For word-unaligned sizes, GNU’s mergesort and our tweaked GNU quicksort are never slower than the baseline; for large items, they are around 4x as quick. On the same input, BSD’s mergesort and our k-ary heapsorts are on par with one another and slightly slower than the baseline, while GNU’s quicksort is slightly quicker. The only sort routine that’s markedly slower than BSD’s quicksort is BSD’s binary heapsort (around 2-3x as slow).
BSD’s word-alignment optimisation makes sense in practice: larger structs will often include at least one field that requires non-trivial alignment. I think it makes sense to look at arbitrary sizes only up to a small limit (e.g., 32 bytes), and then only consider word-aligned sizes.
For small element sizes, all but two routines are comparable to the baseline. BSD’s heapsort is markedly slower, and our tweaked GNU quicksort somewhat faster.
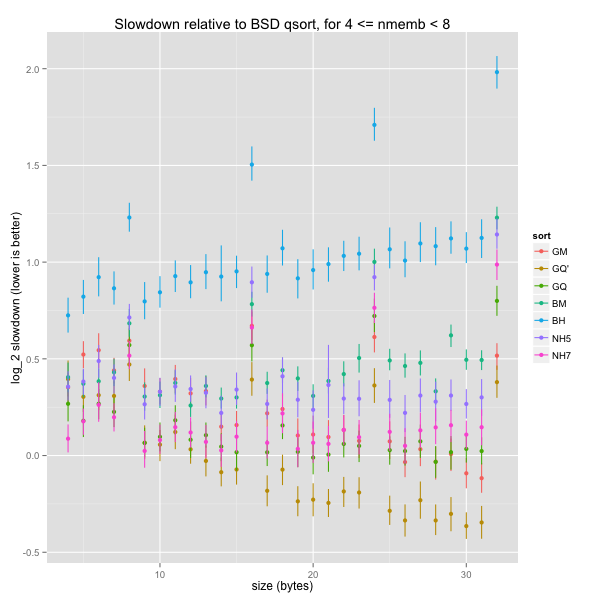
When element sizes are word-aligned, BSD’s quicksort is hard to beat. The only routine that manages to be quicker is GNU’s mergesort, for very large element sizes: the routine exploits dynamic storage to sort pointers and only permute elements in-place during a final linear-time pass. Our k-ary heapsorts remain in the middle of the pack, slightly slower than BSD’s mergesort and GNU’s quicksort.
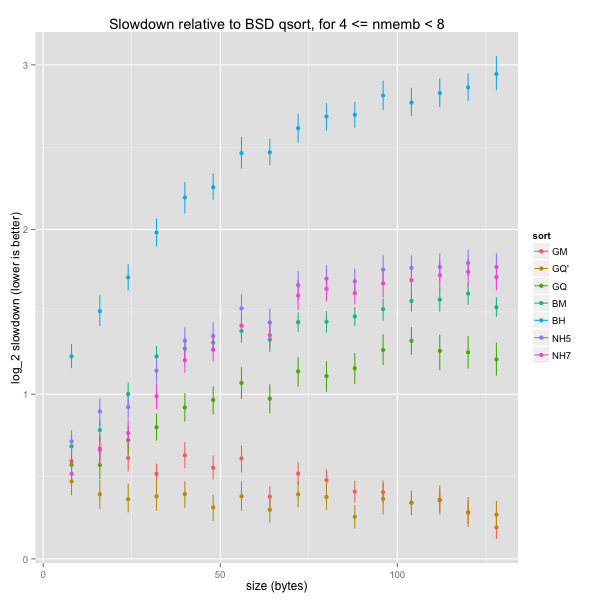
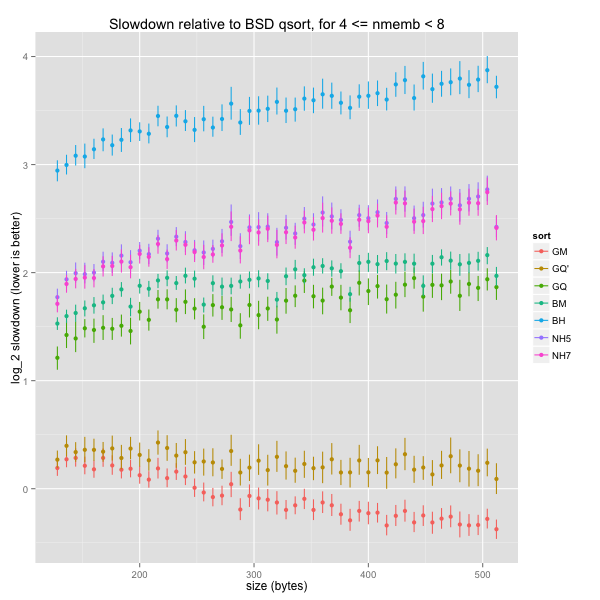
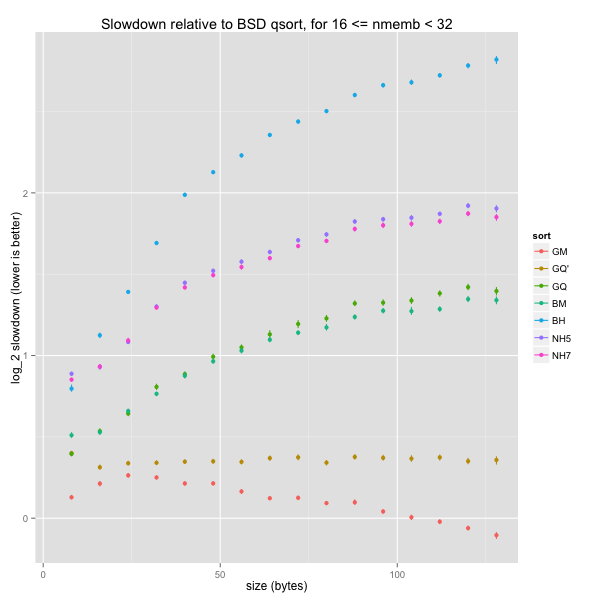
Impact of element size on extra small arrays
The results in the previous section were noisy: that’s expected when sorting arrays of 4 to 7 elements. This section looks at arrays of 8 to 15 elements; there’s less random variations and the graphs are much clearer.
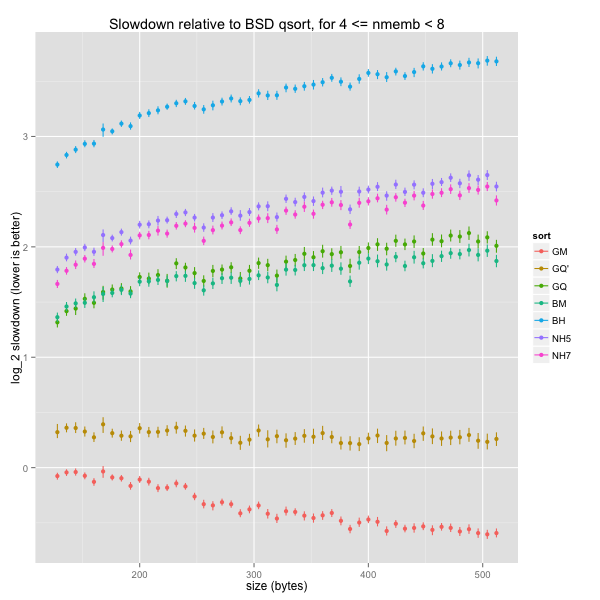
The graph for overall speeds is similar to the one for tiny arrays. However, it’s clear that, for general element sizes, our k-ary heapsorts are slightly faster than BSD’s mergesort and a bit slower than GNU’s quicksort. Again, GNU’s mergesort and our tweaked quicksort are even quicker than BSD’s quicksort.
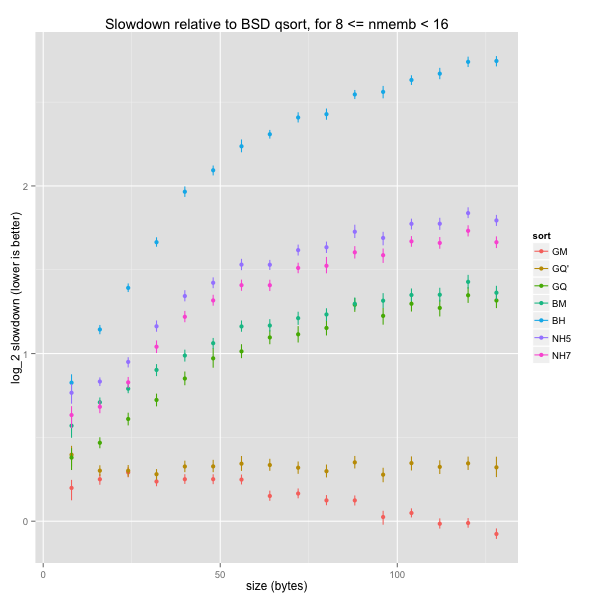
When we only consider word-aligned element sizes, the picture changes. The most important change is that our baseline is a lot quicker, and even GNU’s mergesort is slightly slower than BSD’s quicksort. Our heapsorts are now slower than BSD’s mergesort, which is now comparable to GNU’s quicksort.
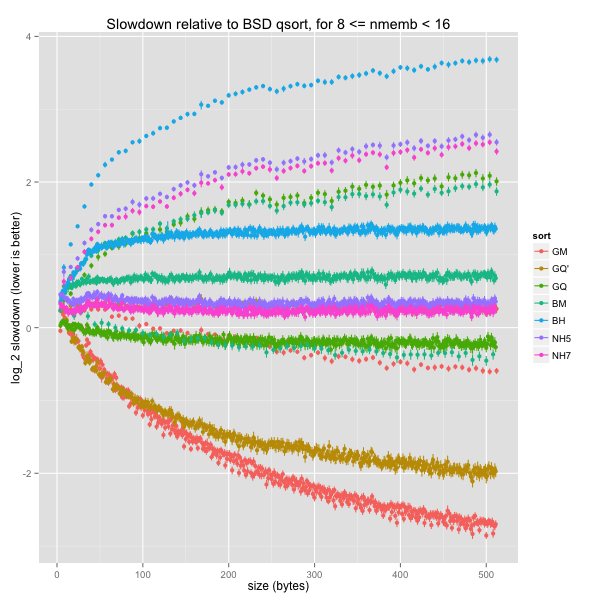
It’s only when we consider almost ridiculous element sizes that GNU’s mergesort edges out BSD’s quicksort: GNU’s indirect sorting strategy finally pays off.
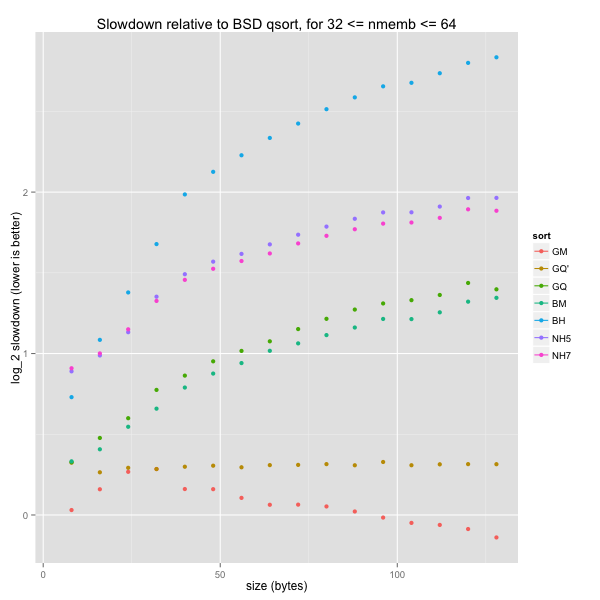
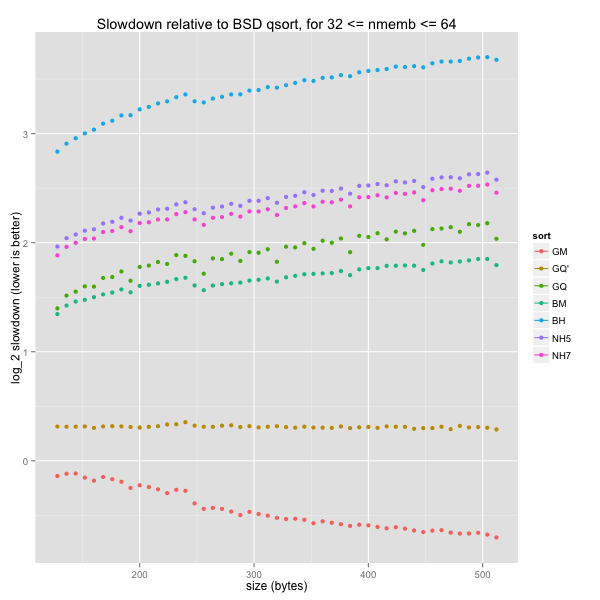
Finally, small and medium arrays
Small and medium arrays lead to the same conclusion as small ones, only more clearly. For arbitrary element sizes, GNU’s mergesort and tweaked quicksorts are much quicker than everything else. As for k-ary heapsorts, they are comparable to BSD’s quicksort and quicker than BSD’s mergesort and heapsort, except for small elements (fewer than a dozen bytes each).
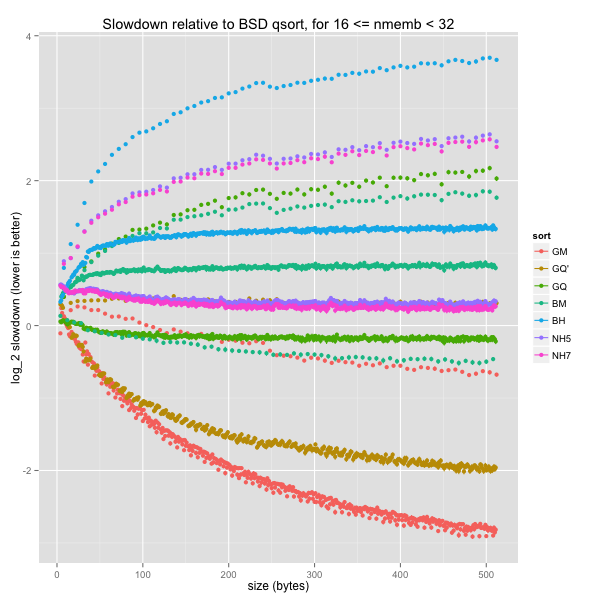
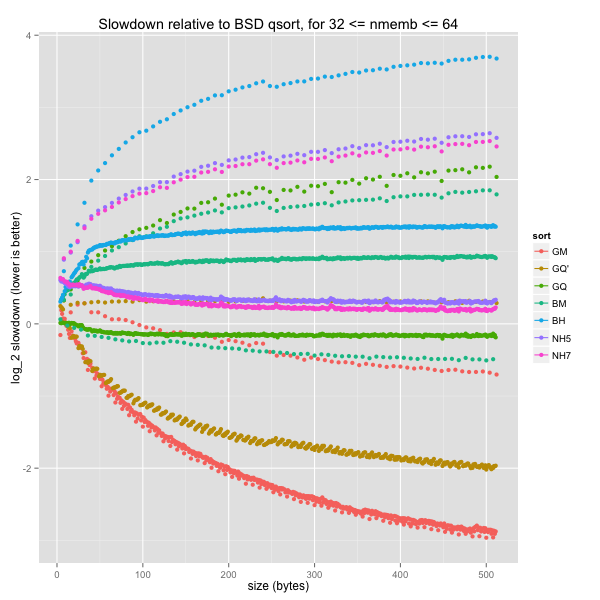
For word-aligned element sizes, GNU’s quicksort is still only outperformed by GNU’s indirect mergesort, while k-ary heapsorts are still slightly slower than GNU’s quicksort and BSD’s mergesort, but always quicker than the latter’s heapsort.
Wrap-up
I’d say our results show that heapsort gets a bad rap because we always implement binary heaps. Higher arity (around 7-way) heaps are just as easy to implement, and much more efficient when comparators are trivial and data movement slow. For small arrays of medium-size elements, k-way heapsorts are competitive with BSD’s mergesort and GNU’s quicksort, while guaranteeing \(\mathcal{O}(n \log n)\) worst-case performance and without allocating storage; they’re almost magical when we only need partial or incremental sorts.
There’s a more general conclusion from these experiments: qsort(3)’s
very interface is a bad fit for a lot of workloads. qsort lets us
implement arbitrary comparisons with a callback, but must rely on
generic swap routines. This probably reflects a mindset according to
which comparisons (logic) are slow and swaps (accessing data)
trivially quick; GNU’s quicksort was definitely written with these
assumptions in mind. The opposite is often the case, nowadays. Most
comparators I’ve written are lexicographic comparisons of machine
words, floating point values, and, very rarely, strings. Such
comparators could be handled with a few specialised sort routines:
lexicographic sorts can either exploit stability (à la bottom-up radix
sort), or recursion (top-down radix sort). However, there were some
cases when I could have implemented swaps more cleverly than with
memcpy(3), and I could always have passed a size-specialised swap
routine. There were also cases when I wanted to sort multiple arrays
with respect to the same key, and had to allocate temporary storage,
transpose the data, sort, and transpose back. Mostly, this happened
because of hybrid
struct of arrays
data layout imposed by memory performance considerations, but
implementing the
Schwartzian transform
in C (which avoids recomputing keys) is basically the same thing. A
swap function argument would be ideal: it’s quicker than generic
swaps, supports memory-optimised layouts, and helps express a classic
Perl(!) idiom for sorting on derived keys.
Behold, the modern sort interface:
struct comparison {
void *base;
size_t stride;
union { void *ptr; unsigned long mask; } auxiliary;
enum comparison_kind kind;
};
void
generic_sort(const struct comparison *cmp, size_t ncmp, size_t length,
void (*swap)(void *, size_t i, size_t j), void *swap_data);
Interpreted DSLs for logic and compiled data shuffling; it’s the future.